2024-11-13
2024-11-13
Epoch AI
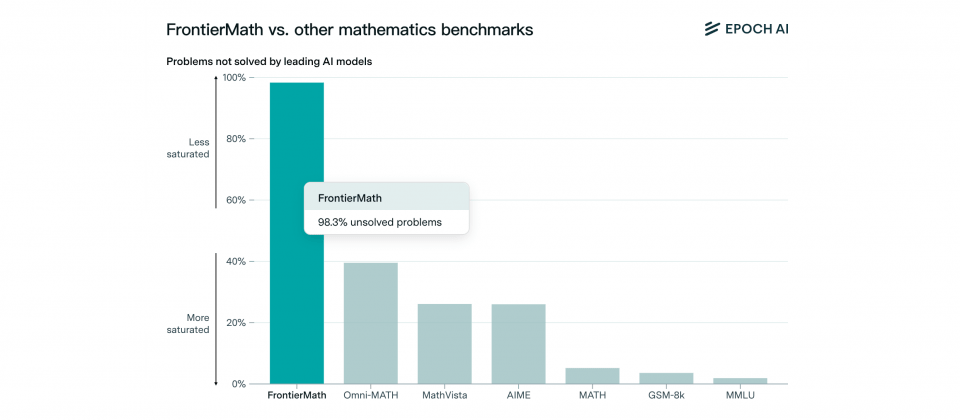
研究机构Epoch AI推出新的数学基准测试FrontierMath,该基准测试的目的在评估人工智能模型的高级数学推理能力。不同于现有数学基准,像是GSM-8K和MATH,FrontierMath中的数学问题更加复杂且专业,涵盖现代数学中的数论、代数与几何等领域,这些题目的难度非常高,专家也需耗费数小时甚至数天才能解答,而这对人工智能模型带来全新考验。
人工智能在解决高级数学题目上遭遇困难,主要问题在于人工智能模型通常仰赖训练数据中的模式来生成答案,而非真正理解和推理问题的逻辑结构,许多模型的解题过程是基于训练数据中类似问题的模式比对,而不是创建在数学上严谨的逻辑推理,这种模式比对的限制,使得模型在遇到稍微变动的数学问题时就容易出错。
要提升当前人工智能模型的数学能力,基准测试不只作为评估人工智能模型数学能力的工具,同时也提供了模型在数学推理能力上具体的进步方向。现有基准测试GSM-8K和MATH,由于问题难度较低,已经被人工智能模型完全解决,导致无法评估人工智能数学推理的上限,而新推出的FrontierMath则补充了现有数学基准测试的不足。
FrontierMath的题目皆为专家全新设计,涵盖多个高级数学领域,难度远超过其他基准测试。这些题目不仅要求人工智能理解数学概念,还需要具备复杂情境的推理能力,避免人工智能通过简单的模式比对或模糊语言生成方式作答。由于FrontierMath题目的答案通常是大数,或是各种具体或抽象的复杂数学元素或结构,使其具有防猜测的特性,通过猜测获得答案的正确概率低于1%。
在FrontierMath初步测试中,目前市场上的人工智能模型表现普遍不佳,即便能够在GSM-8K和MATH达到近乎满分,但是包括Claude 3.5和GPT-4o等知名模型,在FrontierMath的解题成功率均低于2%。研究团队指出,这些挑战不是通过增加模型规模就能解决,需要在算法和推理架构层面深入改进。
多所学术机构的数学专家都参与审查FrontierMath的题目,确保了基准测试的正确性和难度,且不包含任何模糊性。FrontierMath题库还会持续扩充,官方未来会定期发布人工智能模型的测试结果,并与人工智能社群合作以促进学术交流。
目前人工智能模型在数学推理方面的局限性,Apple早前的研究也指出同样现况,人工智能模型大多依赖训练数据中的模式来模拟推理步骤,而非进行真正的逻辑推理。Apple研究人员使用改良过的基准测试GSM-Symbolic测试市面上的模型,研究人员发现,即便是小学程度的数学问题,人工智能模型的表现也受到限制,当改变量学问题中的数字或增加一个额外的无关条件时,模型的解题准确度就会显著下降,甚至达到65%的跌幅。