

 2024-08-16
2024-08-16

Imagen 3为一潜在扩散模型(latent diffusion model),能根据用户输入的文本提示产生高品质图片。Google说,DeepMind团队大幅提升Imagen 3提示理解能力,使模型能生成了解并遵循长而高度描述性的提示,并生成细节繁复、色彩鲜艳、以及视觉设计更丰富的图片。
例如它能理解以下提示,并生成图片:「一个布偶立体模型场景中,出现僻静森林中的静谧画面,中间置入一个网版印刷效果呈现的机器人,它有巨大浑圆的身躯,但十分善良。机器人肩上停着一只猫头鹰,脚边有只狐狸。图片包含5种柔和颜色,并以光线营造宁静和谐的感觉,可激发对自然之美的沈思和赞颂。」
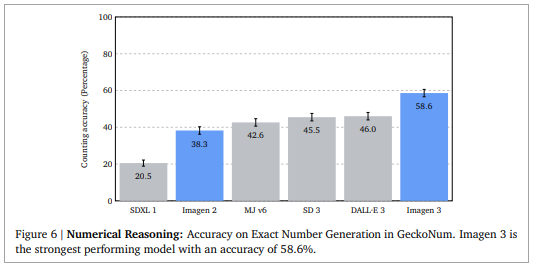
Imagen 3默认可生成1024x1024分辨率的图片,用户可以2倍、4倍、或8倍采样生成想要的图片。DeepMind团队将Imagen 3和Imagen 2与其他知名图片生成AI模型,如DALL-E 3、Midjourney v6、Stable Diffusion(SD)3 Large、SD XL 1.0等进行比较。根据其数据,Imagen 3在生成图片与提示的符合度,仅次于Midjourney 6,但在详细提示的符合度(fig 5),及理解数字的能力(fig 6)则是所有模型最佳。团队也声称生成图片画质技冠群雄(fig 7),并且是最能在图片画质和用户意图间取得平衡的模型。

但Google也承认,Imagen 3的计数能力有待加强,且牵涉规模(如大小)、行为,以及包含复合词的提示,对所有模型都有理解难度。
马斯克的AI公司xAI也在本周公布了图片生成模型Grok-2系列。













