

 2024-12-30
2024-12-30
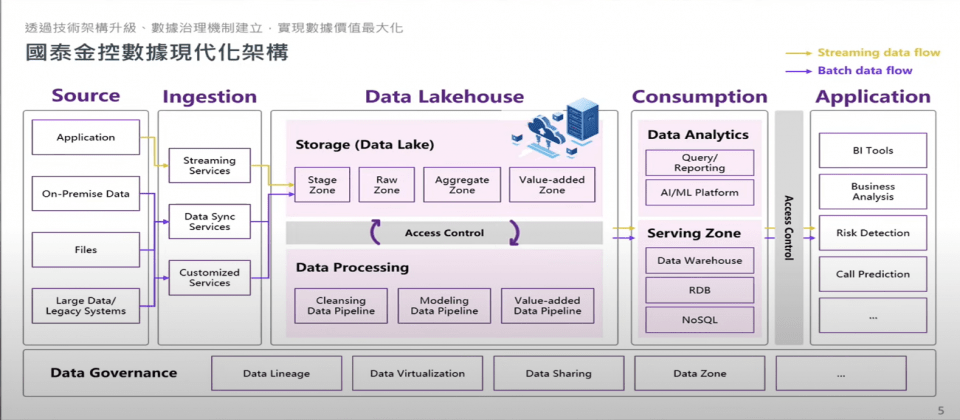
在雲端資料湖倉平臺中,國泰採用自研發的自動化ETL工具PIGEON來進行資料處理,PIGEON能自動生成資料管道,也支援事件驅動機制。(:國泰金控)
另外,在資料使用層中包含一套ML平臺。劉浩翔表示,這套ML平臺包含三大特色,第一,平臺包含AI治理功能模組,具有國泰自行開發的負責任AI工具包,能針對AI模型進行評測。第二大特色,平臺透過容器化技術,將模型從開發、訓練到部署的過程管道化。最後,平臺提供模型中心Model Hub,提供多種模型選擇,包含雲端、地端、開源或閉源模型,也提供標準化API介面,能介接各種服務。Model Hub也提供成本管理功能,協助開發者管控模型使用開銷。
資料治理四大原則
在現代化數據架構中,資料治理層貫穿了所有資料管道,包含了統一元數據管理、資料虛擬化、資料共享,和資料分層管理。
為了提升資料管理的效率與安全性,國泰採用了元數據管理平臺。「這套解決方案將會是未來雲端上的數據治理中的重要基底。」劉浩翔強調,進行元數據管理後,能加速資料調閱與管理,同時做到權限管理和自動化軌跡留存,「未來就有辦法回溯資料血緣,瞭解每個資料取用的上下游脈絡。」
另外,劉浩翔提到,在地端環境管理數據時,往往因缺乏能整合不同資料源頭的平臺,需要經常將資料搬移至集中化儲存空間,才能檢視所有資料的系統來源。然而,「在某些場景中,搬移資料十分困難,常常造成數據孤島問題。」劉浩翔說。為瞭解決這項痛點,國泰運用資料虛擬化技術,透過建立虛擬化中心,快速取得來自不同系統的資料,減少ETL工具的開發成本。同時,透過增加虛擬層,更快完成跨系統間的資料共享。
在資料治理層中,國泰也有進行資料分層管理。當子公司各類系統輸入資料至國泰的雲端湖倉平臺時,資料會經過五個數據分層進行處理,先從暫存數據層進入原始數據層,對資料進行清洗、去敏和加密動作,接著進入數據彙總層,建立資料模型(Data Model),將資料化為通用性較高的資料表,再進入數據加值層,按數據主題產出數據產品的資料市集(Data Mart),例如產出各項風險指標。最後才進到數據服務層,服務業務人員的數據需求。劉浩翔強調,透過數據分層,平臺能區隔明碼區和暗碼區,確保使用資料的人員不會接觸到明碼區。
雲端人才不足,國泰計畫3年對內培育200位雲端數據人才
在推動上雲的過程中,劉浩翔坦言,雲端人才短缺,仍是最大痛點,「所有邁向雲端的業者都會麵臨一個問題,就是雲端人才到底在哪裡?」意識到僅依賴外部招募無法滿足人才需求,國泰啟動名為「雲世代」的培育計畫,目標在3年內對內培養出200位雲端數據人才。
劉浩翔表示,國泰金控計畫每半年會從四間子公司招募40名種子學員,透過系統性課程、期末專題和團體活動,提升種子學員的雲端技能和技術應用能力。培訓結束後,集團會以總經理為首,邀請50位集團長官、主管共同見證培訓結果。
「這項計畫絕對是國泰數據成功上雲的關鍵。」劉浩翔強調,若沒有及早啟動人才培育,即便技術與管理機制完善,缺乏對應的人才支撐,最終仍可能導致計畫失敗。
「雲端和AI息息相關。」劉浩翔期待,國泰邁向雲端後,未來能充分利用雲端算力和已開發的原生服務,「不僅推動業務成長,還能在AI發展上實現雙向賦能,推動業務前進。」












