2024-07-26
2024-07-26
Hugging Face SmolLM 小型語言模型
Hugging Face釋出小又強健的語言模型SmolLM
最近Hugging Face發布一系列語言模型,名為SmolLM,共有3個版本,包括1.35億參數(135M)、2.6億參數(360M)和17億參數(1.7B)版本。為訓練這些模型,Hugging Face還建置了高品質的訓練語料庫SmolLM-Corpus,由3大類語料組成,分別是目前最大的合成教科書和故事資料集Cosmopedia v2,共有280億個字元(Tokens),以及程式碼教學範例資料集Python-Edu、篩除重複範例的網路範例資料集FineWeb-Edu。這個SmolLM-Corpus語料庫,也隨著模型一起開源。
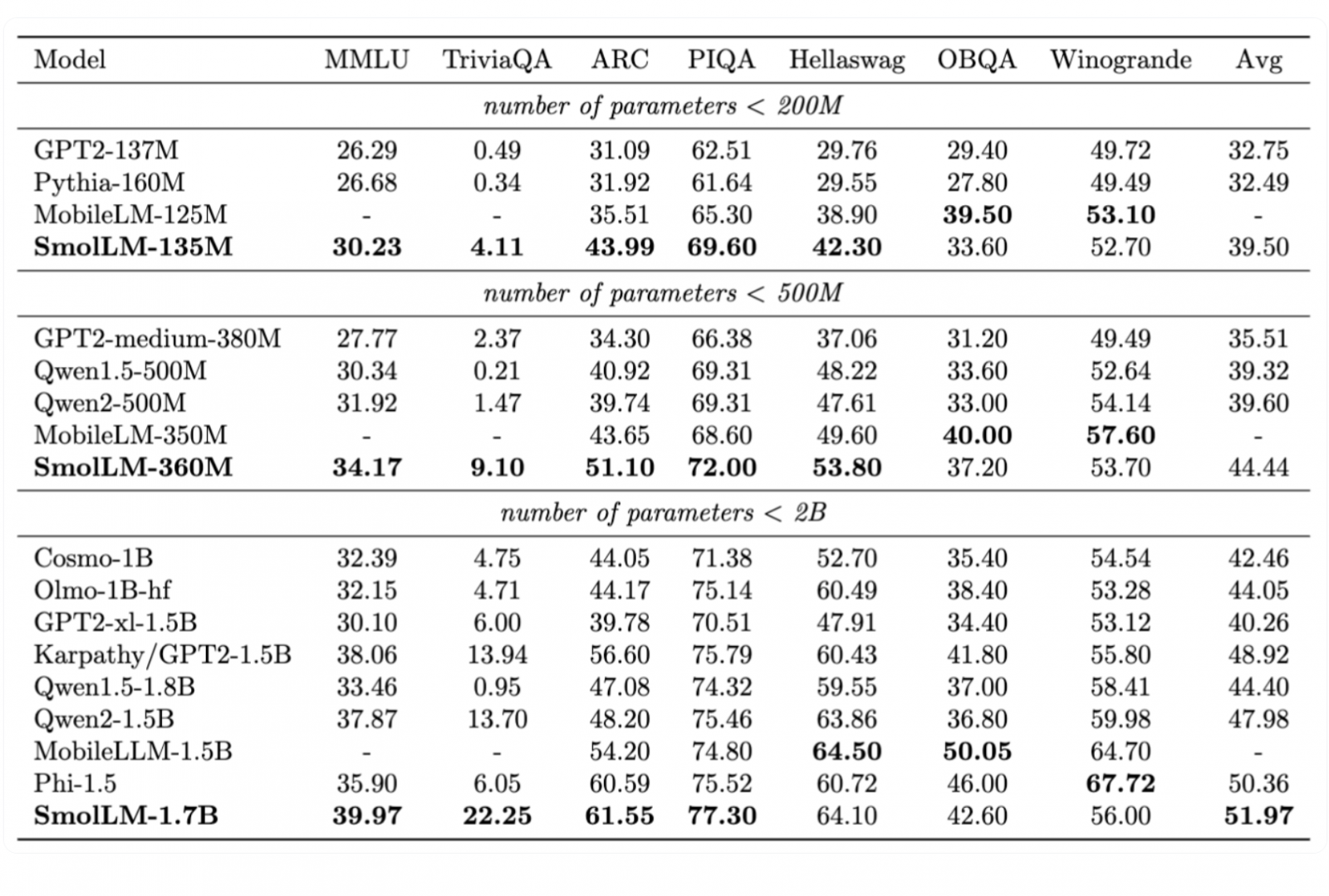
就模型效能來說,SmolLM在各種常識推理和世界知識測試中表現優異,超越了同規模的MobileLLM、Phi-1.5和Qwen模型。這一系列小型模型,有助於AI在各種裝置上執行,提高應用性。(詳全文)
Llama 3.1 Meta 開源
Meta終於開源Llama 3.1 405B了
日前,Meta開源了Llama系列語言模型的最新款Llama 3.1 405B,具4,050億個參數,脈絡長度達12.8萬個字元(Token),支援8種語言,是Meta迄今開發的最大模型,號稱是全球第一個達頂尖水準的開源模型。Meta創辦人暨執行長祖克柏還特別強調開源AI的重要性,認為開源纔是AI的未來。
進一步來說,該模型有2個版本,包括Llama 3.1 405B和Llama 3.1 405B Instruct。Llama 3.1 405B是在近15兆個Token上進行訓練,經測試,Llama 3.1 405B在通用基準測試IFEval、數學測試GSM8K、推論測試ARC Challenge等測試中,都勝過GPT-4、GPT-4o和Claude 3.5 Sonnet。但在人類專家評估中,則與GPT-4-0125、Claude 3.5 Sonnet的表現不相上下,但明顯不及GPT-4o。(詳全文)