2023-02-26
2023-02-26

这一章主要介绍的内容是关于网站结构优化,内容我自己先是在去河南的飞机上看过一遍了,今天又重新看了一遍,整体上对于小白(虽然我也是小白TAT)来说,因为涉及许多比较专业的名词,还涉及到代码,比较复杂和枯燥。
其实我们大多数人建站都是用shopify和wordpress,有许多书中列出的问题我们并不会遇到,所以我会尽量挑重点写下来,略过一些复杂繁琐的东西。
废话不多说,开始吧~
许多人可能不了解什么是网站结构,我自己的理解是这样的:
我们的网站,其实是由许许多多的页面组合而成的。我们在实际上网的过程中,就是在不同的页面之间跳转——就像我们在看一本书。想象一下,我们打开一本书,首先有非常详细的介绍,告诉我们第一章是什么内容,第一章的内容是第几页到第几页。得益于清晰的目录和书页的排版,你可以根据自己的喜好,随意地翻到你想看的页面。那么假如我把这本书的每一页都撕下来,最后随意的粘贴在一起,那么这本书就会看起来乱七八糟,因为你完全找不到你想看的内容,就算你找到了,可能你看完一页,却发现第二页并不是上一页内容的衔接。
所以从上面的例子我们可以看出,我们的网站也要像一本排版工整且有逻辑性的书,第一页是什么,第二页是什么,第一章应该说什么,都要有一个清晰的结构,进入我们网站的客户才能找到他想要的内容或者产品。
一、网站结构优化的目的
1.用户体验
做网站结构优化的首要目的就是让用户访问网站的时候,能够清晰的知道自己在哪个页面,页面上面有什么内容,想去别的页面要怎么点击进去。同时提一句,用户在网站的行为方式也会被计入到排名算法内。
2.收录
一个良好的网站结构有利于搜索引擎的收录。而我们seo的整个目的也是尽可能地促进网站页面被搜索引擎收录。
3.权重分配
除了外部链接能够给某个页面带来权重之外,网站本身的结构以及链接关系是内部页面权重分配的重要因素。我们要有意思地规划好网站所有页面的重要程度,然后通过链接结构把权重更多地导向重要的页面。
4.锚文字
锚文字是排名算法很重要的一部分。网站内部的锚文字是我们所能够控制的,所有这是增加关键词相关性的方法之一。在这方面我们可以多向维基百科学习。
二、对搜索引擎友好的网站设计
如果我们从搜索引擎的角度去看待一个网站,当搜索引擎在抓取,索引,排名的时候会遇到哪些问题?而解决了这些问题,就说明我们的网站对于搜索引擎是友好的。
1.搜索引擎能不能找到网页
想要让搜索引擎蜘蛛找到网页,那么首先就需要有外部链接。而当搜蜘蛛顺着外部链接进入我们的网站时,想要让蜘蛛爬取到我们更多的网页,我们就必须有良好的结构。网站内所有的页面最后距离首页不超过4-5次的点击。
2.找到网页后能不能抓取页面内容
URL含有过多参数,整个页面是Flash,框架结构,可疑的转向,大量复制的内容,都可能使蜘蛛不愿意抓取。
3.抓取页面后怎样提炼有用信息
关键词在页面重要位置的合理分布,重要标签的撰写,HTML代码精简,起码的兼容性,都有助于搜索引擎理解并提炼重要信息。这一部分的内容会在后面关于“页面优化”再展开。
三、避免蜘蛛陷阱
有些网站的设计对于搜索引擎非常不友好,这些技术被称为蜘蛛陷阱,主要包括以下这些:
1.Flash
网页的绝大部分都是Flash,这非常不利于搜索引擎抓取和理解页面内容。
2.Session ID
有些网站会使用session id跟踪用户访问,会导致URL变化,不利于蜘蛛抓取。应使用cookie代替。
3.各种跳转
除了301跳转外,搜索引擎不喜欢任何其他形式的跳转。
4.框架结构
这一点的解释我没看懂。但是作者说了,如果我不知道什么是框架结构,那么恭喜我,我已经避免了这个陷阱……好吧,第一次因为无知而得福。
5.动态URL
网站的网址是有数据库驱动生成带有问号,等号,参数等网址。这种动态的URL对客户和蜘蛛都是不友好的。
6.JavaScript链接
使用javascript可以制造出吸引人的视觉效果,但是不利于搜索引擎解析。
7.要求登录
网页的内容设置为必须登录才能查看。但是蜘蛛可不会填写信息登录,所以只会导致整个页面不能被爬取。
8.强制使用cookie
有些网站强制用户使用cookie,如果用户没有启用cookie,页面的显示就不正常。显然,这也是要避免的。
四、物理结构与链接结构
1.物理结构
物理结构是网站真实的目录及文件所在的位置决定的结构。
这一点我们可以想象一下我们电脑上的文件夹。
我们经常把一些文件存放于某个硬盘下的某个文件夹内的某个文件夹内。当然,如果这份文件是你的小秘密,你可以存放地更深……
一样的道理,我们的网站是由网页组合成的,每个网页就像一份文件,我们存放在服务器上面。所以,一般的物理结构就像这样:
http://www.domain.com/catA/product-a.html
http://www.domain.com/catA/product-b.html
http://www.domain.com/catB/product-a.html
http://www.domain.com/catB/product-b.html
……
2.链接结构
链接结构也称为逻辑结构,是网站内部链接形成的网络图。
简单理解就是我们给网站不同的页面设置的一个跳转逻辑,比如网站首页是H,我们指定好了,H页面能够跳转到C1和C2页面,而C1页面又可以跳转到P1页面。
其实对于大多数人(比如我这种操盘小网站的……)来说,我们只要关心链接结构即可。典型的链接结构是树形结构,如下:
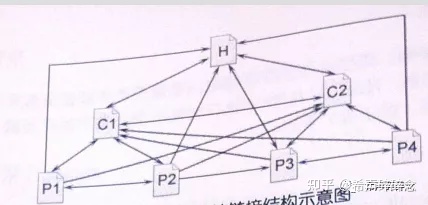
其中每个代码代表了一个网站页面。
网页的收录是否容易,与页面处于链接结构的什么位置,距离首页有几次点击有关,与目录层次(物理结构)无关。
五、清晰导航
清晰的导航主要要解决这两个问题:
1.让用户知道我现在在哪里
2.让用户知道我下一步要去哪里
站在SEO角度,网站的导航系统应做好以下几点:
1.文字导航
导航使用最普通的HTML文字,利于抓取。
2.点击距离以及扁平化
导航是把所有页面链接起来的一只手,要尽可能使所有页面距离首页的点击不超过4.5次。
3.锚文字包含关键词
导航中要考虑使用关键词,但是不能堆积,2-4字为宜。
4.面包屑导航
以下图片标红框的位置就可以称为面包屑导航。建议使用。
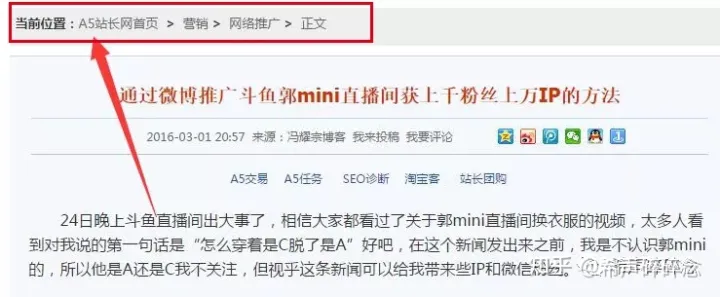
5.避免页脚堆积
建议避免在页脚堆积关键词,可能导致搜索引擎惩罚。
六、子域名和目录
子域名和主域名是两个完全不同的网站。主域名获得外链提高权重,子域名并不会得到提高。所以对于大多数人(比如我这种操盘小网站的……),并不需要使用子域名。
举例如下:
http://www.domain.com
http://news.domain.com
这是两个不同的网站。
而http://www.domain.com/news就纯粹是http://www.domain.com/的一部分。
七、禁止抓取、收录机制
这一项内容对于大多数人(比如我这种操盘小网站的……)并不需要,所以我只罗列出来,不详细展开。
有的时候,我们不希望某些页面被收录(或者说索引),如付费内容,还在测试的网站,或者是些无意义重复的内容。那么我们可以通过以下手段确保页面不被抓取:
1.robots文件
撰写robots文件,就是在提醒搜索引擎,哪些页面禁止抓取。robots文件不存在或者为空都意味着允许搜索引擎抓取所有内容。
但是要注意的是,被robots文件禁止抓取内容,但该页面的URL还是可能被索引并出现在结果中。想要URL完全不出现在搜索结果中,就需要使用下面这个标签。
2.noindex meta robots标签
使用了noindex meta robots标签的页面会被抓取(只要robots文件没有禁止),但不会被索引(收录)。
注意:抓取和索引(收录)是两个不同的概念。robots文件的作用是禁止抓取,但不禁止索引,meta noindes的作用是禁止索引(收录)。
3.nofollow的使用
nofollow能阻止蜘蛛爬行和传递权重。
一条外链就像一个信任投票,是一个权重的传递。但是当我们只是想要做一个链接,并不想传递权重或者投出这一个信任投票,我们就会使用到nofollow。
一般的用途就是减少垃圾外链。用在博客评论,论坛帖子,社会化网站,留言板等地方。还有个重要用途就是广告链接。
八、URL静态化
有许多网站是由数据库驱动,页面由程序生成。并不是我们一般小网站那样,每个页面都是站长手动创建的。那么就会导致URL是动态的,如这种:
https://image.baidu.com/search/detail?ct=503316480&z=0&ipn=d&word=%
包含了许多参数,不利于搜索引擎抓取。
对于大多数人(比如我这种操盘小网站的……),我们的网站的所有页面基本都是自己手动创建的,那么基本不存在URL动态化的问题,所以就不展开了。
九、URL设计
URL设计要遵循以下几个注意点:
1.URL越短越好
2.避免太多参数
这主要是针对动态URL。尽量使用静态URL,如必须使用动态URL,则参数最好在2-3个以内。
3.目录层次尽量少
这里指的是物理目录结构。
4.文件及目录名具描述性
URL具备一定的描述性,不要都是无意义的单词。
比如:http://www.domain.com/news/finance就比http://www.domain.com/cd01-z/sub-a好得多。
5.URL中包含关键词
英文网站关键词出现在URL中,能稍微提高权重,且有利于用户体验。中文网站就不必勉强,URL中出现中文字符,容易显示为乱码。
6.子母全部小写
7.连字符使用
搜索引擎把URL中的短横线,也就是连字符(-)当做空格处理,所以单词之间一般用(-)分隔,不要使用其他奇怪的符号。
十、网址规范化
网址规范化指的是搜索引擎挑选最合适的URL作为真正网址的过程。
举例来说:
http://www.domain.com
http://domain.com
http://www.domain.com/index.html
这三个URL一般指的是同一个文件。虽然这些网址返回的是相同的文件(网页),但是从技术上来说,完全可以对这几个网址返回不同的内容。