

 2024-02-19
2024-02-19
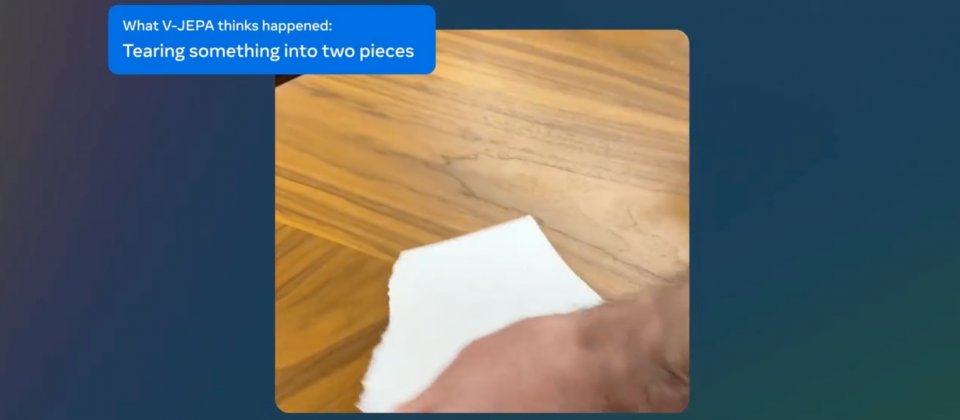
研究人員解釋,如果僅是隨機抽選遮蔽影片中的小區塊,則會讓任務過於簡單,使得模型無法真正學習到關於世界的複雜事物。因此Meta特別制定涵蓋空間與時間的遮蔽策略,迫使模型學習並且發展對場景的理解,進一步預測未來的事件或是動作,進而達到對世界更深層次的理解。
該方法的優勢讓模型能夠專注於影片的高層次概念,而不會鑽牛角尖於對下游任務不重要的細節,像是人類觀看在有樹木的影片,不會特別關心每片葉子的細微動作一樣,如此便能提高了學習效率和任務適應性。
V-JEPA還有一個重要的創新是凍結評估(Frozen Evaluations)的能力,模型在預訓練之後,核心的部分不會再改變,因此只需要在其上添加小型專門層即可適應新任務。該設計避免了傳統模型針對新任務需要全面微調的麻煩,減少學習新任務的資料和時間要求,並使得模型能夠在不同任務中重複使用,諸如動作分類、精細地物體互動辨識以及活動定位等。
Meta會繼續擴展V-JEPA模型,從只有處理影片的視覺內容,增加整合音訊實現多模態學習,研究團隊認為,透過更豐富的上下文資訊,將能夠加深模型對影片內容的理解。此外,他們也會繼續強化模型長期規畫和預測能力,使其能夠處理長時間跨度的任務,而這將是發展高階機器智慧的重要方向。Meta現在以創用CC BY-NC授權釋出V-JEPA模型,促進人工智慧領域發展。













