

 2023-12-22
2023-12-22
Google发布机器学习最新研究,目的是通过改善机器学习编译器,来提升机器学习工作负载的执行效率,借由采用机器学习技术优化编译器决策,进一步增加机器学习模型的性能。作为研究的一部分,Google还推出了新数据集TpuGraphs,用以促进机器学习程序优化研究。
随着机器学习技术不断发展,现在的机器学习系统已能理解自然语言,生成对话、图像和视频等。而这些先进的机器学习模型,主要使用TensorFlow、JAX与PyTorch等机器学习程序开发框架开发和训练而成,这些框架提供了诸如线性代数运算、神经网络等高端功能。
由于机器学习框架通过底层编译器,自动优化用户的模型,因此机器学习工作负载的性能,很大程度取决于编译器的性能,研究人员指出,由于编译器通常依赖启发式方法来解决复杂的优化问题,而这也常造成性能不佳的原因。
机器学习编译器可以将用户编写的程序转换成为可在硬件上运行的可执行指令,机器学习编译器必需要解决许多复杂的优化问题。而强化机器学习编译器的性能,也就能够提升机器学习模型的性能。
在编译器优化策略中,分配内存布局给所有中介张量是一个关键的环节,内存布局可以有不同的排列方式,常见的包括列优先与行优先布局,在机器学习的程序中,编译器需要决定每个中介张量的内存布局,而布局的优化会影响计算效率。
编译器在分配内存布局时,需要权衡局部运算效率和内存布局转换成本,而这个布局分配优化的目的,便是在计算效率和内存管理间,找到一个最佳平衡点。机器学习技术便可被用来找到该平衡点,通过分析程序的不同特性,像是操作种类、数据大小和结构,预测可以提供最佳性能的内存布局。
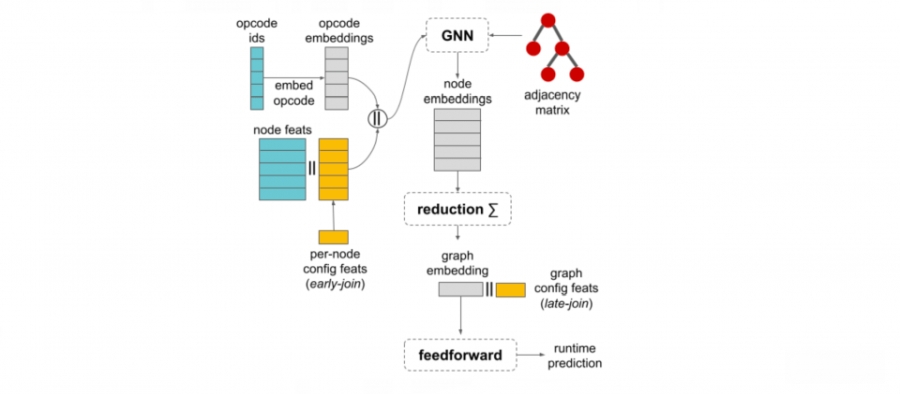
在编译器中运用学习成本模型,就能有效协助改进经编译的机器学习模型效率。输入程序和编译器配置到学习成本模型中,模型便会输出程序执行时间预测。
虽然原本就存在一些用于程序性能预测数据集,但主要是针对小型子程序,为此,Google创建了TpuGraphs数据集来训练学习成本模型,特别是针对大型的计图像运算(Computational Graph)。由于这是一个用于Google机器学习加速器TPU执行程序的学习成本模型数据集,因此称作TpuGraphs,主要针对两种XLA编译器配置,涵盖了布局和切割(Tiling)。
数据集中的样本,包含了机器学习工作负载的计图像运算、编译配置,还有使用该配置的执行时间。数据集的内容来自于开源机器学习程序,涵盖多种热门模型架构,像是ResNet、EfficientNet、Mask R-CNN和Transformer等。
与之前的图属性预测数据集相比,TpuGraphs数据集图的数量是25倍,平均图大小比现有的机器学习性能预测数据集大770倍。官方指出,随着数据集的扩大,研究人员第一次可以探索大图上针对图层级的预测任务,解决包括可扩展性、训练效率和模型品质等问题。
Google还采用了一种称为GST(Graph Segment Training)的训练方法,解决在内存容量有限的设备上,训练大型图神经网络的问题。该方法使端到端训练时间加速达3倍,有效提高训练的可行性和效率。
该篇研究的具体贡献是将机器学习技术,用于优化XLA编译器配置,加速编译后模型的执行效率,另外,Google发展TpuGraphs数据集和GST训练方法高效训练学习成本模型,预测机器学习程序在特定编译器配置下的执行时间,以此作为优化模型的基础。













